
Accuracy is key for any data analysis and with Inspirient, we can now produce even higher quality data.
No one wants to end up making decisions based on incomplete, faulty or biased survey data. But gathering high-quality data from public opinion polls or surveys is not easy and certainly does not come for free. Hence, leaders in the survey and polling industry, such as Verian, are continuously monitoring their data as it is being collected, with the clear aims of both addressing any data quality issues as they arise and ensuring that they deliver the most trustworthy and reliable results to their clients.

- Anomaly detection in 'no opinion' answers and evaluation of response entropy
- Scoring of speeders and straightliners, joint evaluation and prioritization
- Quantitative checks for biases introduced by certain interviewers
Usage of Automated Analytics
Leveraging the capabilities of Inspirient's Automated Analytics Engine, the Verian Data Innovation Hub has succeeded in defining and implementing a number of advanced survey quality checks that can be applied automatically to their panel data as it is being gathered during fieldwork. Further, this new and improved Survey Quality Assessment also benefits from supplementary checks from adjacent fields now being applied to surveys, incl. from financial fraud detection, that help address any unknown unknowns and even adversarial data providers.

Given the very high degree of automation of these checks, Verian is now able to continuously monitor the data gathering process, immediately take appropriate action should their high standards for data quality ever not be met, and then proceed with confidence to scan the gathered data for relevant results.
Innovation and Benefits for Verian
In detail, the improved data quality checks at Verian now also comprise...
- Evaluations of 'no opinion' answers and response entropy to ensure any subsequent analysis is carried out on a sufficiently rich data basis
- Scoring-based detection of speeders and straightliners that employs a gradual scoring mechanism to prioritize cases to be discarded and cases to be validated manually
- Quantitative checks for biases introduced by certain interviewers, incl. statistical metrics that don't rely on pre-defined rules, that allow to granularly steer the fieldwork
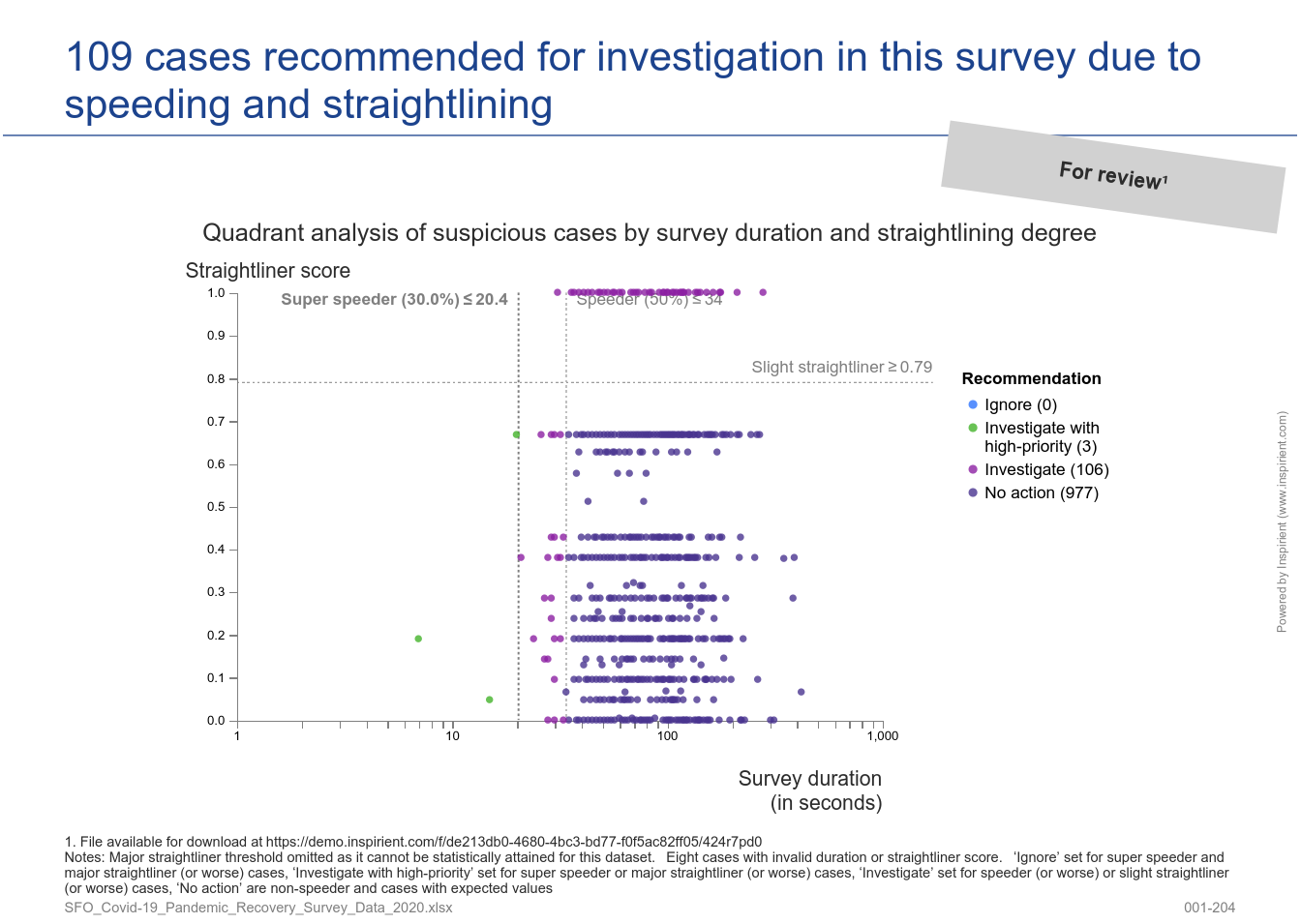
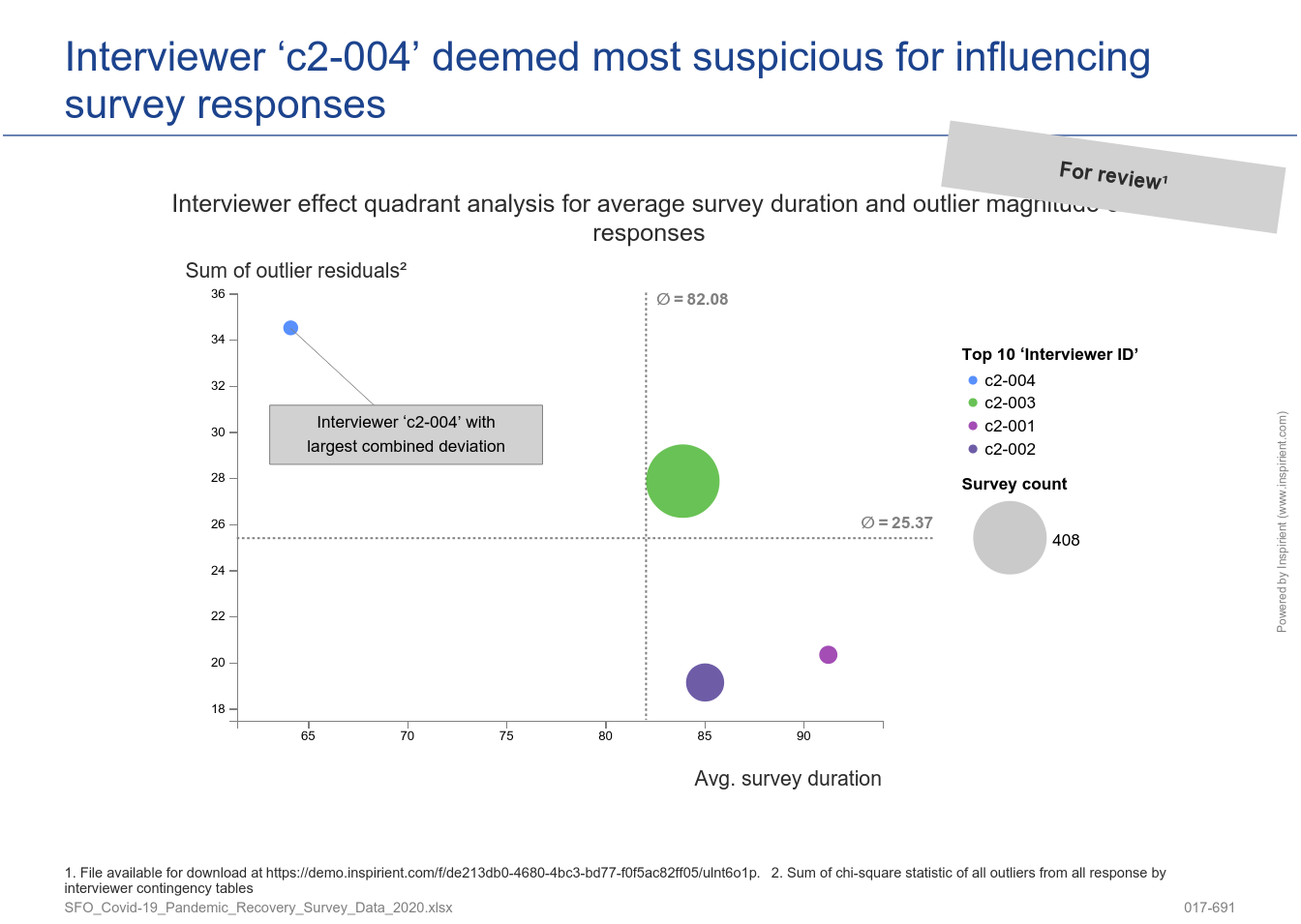
All of these checks are applied automatically to any gathered survey data and a comprehensive report is generated automatically, incl. recommended next steps for the consideration of the experts at Verian. For additional background, please check out the detailed analytics of our Survey Quality Assesssment.
Conclusion
With these survey quality checks in place and being applied automatically to incoming survey data, the quality of survey and polling data can be documented in unprecedented detail throughout the fieldwork phase. This enables Verian to guarantee the most trustworthy and reliable insights to their clients.
The Inspirient Automated Analytics Engine automates the entire data analytics process end-to-end: From the assignment of input data, pattern and outlier detection, automated visualization of patterns, weak points and opportunities to automatic generation of textual explanations and recognition of the underlying relationships and rules. Most other analytics solutions rarely include these textual explanations and observations regarding the underlying data relations, which are both critical to provide a deeper level of analysis and more actionable conclusions.